This is the multi-page printable view of this section. Click here to print.
- 1: Installing the cuttle CLI
- 2: Authenticating with the cuttle CLI
- 3: Configuring the cuttle CLI
- 4: Operating with the cuttle CLI
- 5: Help commands
1 - Installing the cuttle CLI
You can install the cuttle CLI by following the instruction below for your particular operating system:
- Download the cuttle CLI either for Apple M-series or Intel architecture.
- Change the downloaded file’s permission to be executable:
chmod a+x cuttle - Let’s remove the macOS file quarantine feature
with the following
xattrcommand:xattr -rd com.apple.quarantine cuttle - Place the file to be reachable, as under /usr/local/bin:
sudo mv cuttle /usr/local/bin
- Download the cuttle CLI for Windows: Windows (x86_64)
- In Windows environments, a security warning may appear when downloading the cuttle command executable.
If you receive the following warning in Microsoft Edge, follow the screenshot to save the file.
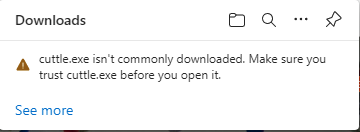
Example of the security alert message.
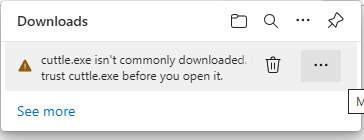
Mouse cursor over the message to see ….
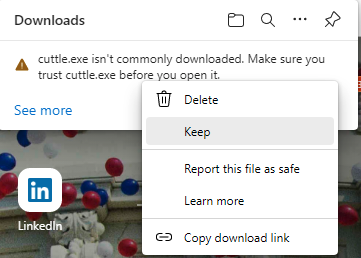
Click on … and select Keep.
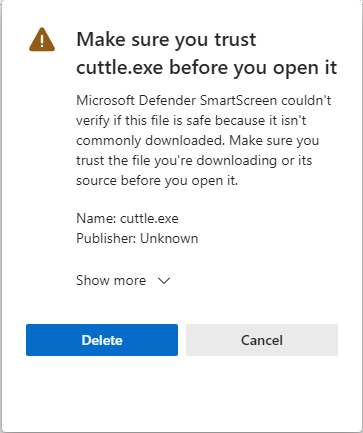
An additional warning message appears, click Show More.
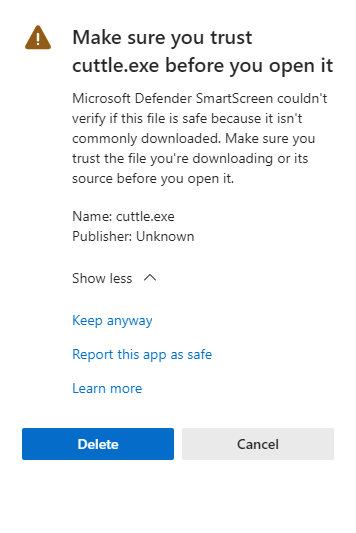
Keep anyway will appear, click to save the file.
the cuttle command is invoked using Command Prompt or PowerShell. For the command prompt, type “cmd” in the Start menu to display the application.
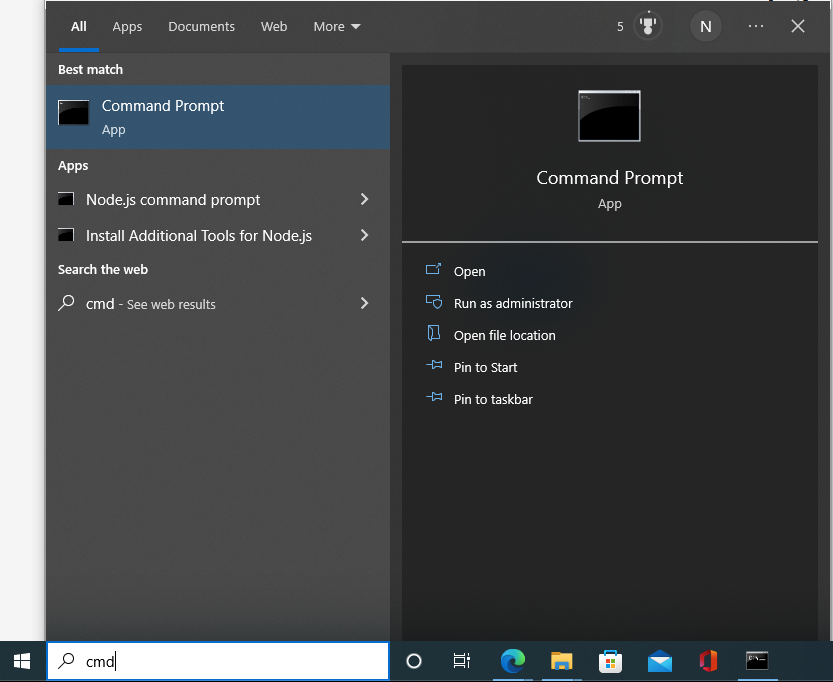
Type cmd in the Start menu search window.
Next steps
Once you install the cuttle command, please authenticate your account or optionally configure your cuttle context.
2 - Authenticating with the cuttle CLI
To authenticate using the cuttle command, execute the following command:
$ cuttle auth login
Please log in in the newly opened browser tab and confirm verification code: PFDT-BHFD
Waiting for successful authentication...

Confirm button of the Device Confirmation pane.
confirm the verification code above matches the one on the browser and finish the oAuth step with your Authenticator app on your phone.

Successful authentication of your account.
After successful authentication, cuttle will store refresh tokens in local config. It will use them to obtain fresh auth tokens when accessing EdgeLQ. However, when refresh tokens eventually expire, you will get errors like these:
request failed: rpc error: code = Unauthenticated desc = transport: per-RPC creds failed due to error: oauth2: "invalid_grant" "Unknown or invalid refresh token."
In that case, you will need to use the cuttle auth login command
again.
If you have multiple accounts, it is advisable to specify which account you refresh with:
cuttle auth login --account-name <AccountName>`
This account name may usually have email format xyz@mail.com, but
verify with cuttle config account list.
To verify current account you are using, you can list current contexts
and see which one is ACTIVE - it will show associated account name:
cuttle config context list.
3 - Configuring the cuttle CLI
SPEKTRA Edge Context
The cuttle command can switch between multiple settings (called contexts); one context is associated with an Environment and an Account.
To retrieve contexts, use cuttle config context list. This command
displays all contexts contained in the configuration file. Contexts that
are currently enabled are marked with ACTIVE.
Use the cuttle config context set command to add or change contexts.
This command creates a new context if the specified context does not exist,
or updates the existing value if it already exists.
The following is an example of a command that sets the environment and
account respectively in a context named $CONTEXT_NAME.
cuttle config context set $CONTEXT_NAME \}
--environment $ENVIRONMENT_NAME \
--account $ACCOUNT_NAME
| Options | Description |
|---|---|
--active |
Use the current context instead of specifying a context name. In the above example, ߋ$CONTEXT_NAME is no longer needed. |
--environment |
Specify the name of the environment to use in the relevant context. |
--active-environment |
Set the environment enabled for the current context to the relevant context. |
--account |
Specifies the name of the account to use in the relevant context. |
--active-acount |
Set the account enabled in the current context to the relevant context. |
--default-values |
Specifies the values to use by default in the relevant context (see below). |
--default-value-set |
Specify values to be used by default in the relevant context (see below). |
To see list of environments or accounts, you can use:
$ cuttle config environment list
$ cuttle config account list
Context Default Values
Use --default-values or --default-value-set to set default values
for projects and regions used in context. This way you can avoid specifying
--project or --region params when accessing EdgeLQ API.
The following is an example of how to set up a project with $PROJECT and
a region with $REGION.
cuttle config context set --active --default-value-set project=$PROJECT,region=$REGION
To set individual values, specify --default-values.
cuttle config context set --active --default-values project=$PROJECT
If you want to remove the default value, give only the key.
cuttle config context set --active --default-values project
SPEKTRA Edge Environments
The environment (Environment) does not need to be edited by the user if only the commercial environment is used. The settings for the commercial environment are automatically set by default.
If you need an access to staging environment, you can add it with the following command:
## Add environment
cuttle config environment set stg01b \
--auth-domain auth-dev.edgelq.com \
--domain stg01b.edgelq.com \
--auth-client-id zQvQ3Js18JLKwySX3haxGLhQ4QgRle4Z
## Add context using new environment. Use current account.
cuttle config context set stg01b --environment stg01b --active-account
## activate context
cuttle config context activate stg01b
## go back to default (production)
cuttle config context activate default
SPEKTRA Edge Accounts
The cuttle command allows you to switch between multiple accounts (including service accounts).
A list of accounts can be obtained at cuttle config account list.
To register a new account, use cuttle auth login.
To switch the account used in the current context, give the
cuttle config context set command --account or --active-account.
Login Automation
When using the cuttle command in an environment without human
intervention to automate the process, the use of a service account
avoids the periodic re-login with cuttle auth login and the MFA
processing required for it.
Using ServiceAccount as an Account
By default, cuttle uses User as an Account when accessing EdgeLQ. It is
possible also to use ServiceAccount, more recommended for automated access.
You can create ServiceAccount in a project, if you don’t have one. Note it requires you already have configured cuttle:
# Create service account resource. Each ServiceAccount has its own region,
# but it can use still all the regions (public keys are shared).
$ cuttle iam create service-account $ACCOUNT_ID --parent projects/$PROJECT/regions/$REGION
# Create service account key - and store creds in a file.
$ cuttle iam create service-account-key $KEY_ID --parent projects/$PROJECT/regions/$REGION/serviceAccounts/$ACCOUNT_ID \
--algorithm RSA_2048 --credentials-output-file credentials.json
Assigning roles to ServiceAccount is out of scope of this document, refer to IAM specification.
Once you have credentials.json file, you can add it to the cuttle:
$ cuttle config account add-service-account credentials.json
You can see new account in the list obtained by cuttle config account list.
You may then create new context using this new account name:
$ cuttle config context set <contextName> --environment <envName> --account <accountName>
4 - Operating with the cuttle CLI
The SPEKTRA Edge controller consists of multiple services, and the cuttle
command also consists of corresponding subcommands. For example,
the subcommands cuttle devices, cuttle limits, cuttle iam, and
cuttle monitoring directly correspond to the devices, iam, limits, and
monitoring services. Default cuttle offers access to core SPEKTRA Edge
services.
For specialized ones, built-on top of SPEKTRA Edge (like watchdog), cuttle is
slightly different: cuttle-watchdog v1alpha2 <subcommand> <collection> ....
Note that this specialized cuttle requires API version to be provided as
first argument. Regular cuttle as of now does offer only the newest (v1)
version.
Almost all resources related to SPEKTRA Edge support the Create, Read, Update,
and Delete (CRUD) operations. cuttle supports the create, get, batch-get,
list, watch, update, and delete subcommands, respectively.
Usually, after specifying service and command, you need to specify resource type.
As an example, if you want to list all device resources on the devices service
in a project, run the command cuttle devices list devices --project $PROJECT.
Similarly, to retrieve the Role Binding resource named
projects/test/role-bindings/rb01 on the IAM service, execute the command
cuttle iam get role-binding projects/test/role-bindings/rb01.
Apart from standard CRUD, cuttle exposes custom API calls as well, like
cuttle devices ssh <deviceName>. To see custom commands in a service, you
can invoke cuttle <service> --help.
Command restrictions
Some of the features provided by the cuttle command may have limitations depending on the operating system. The following is a list of commands that are restricted on the certain environment:
| Command | Supported OS |
|---|---|
| cuttle os install | Linux environment only (for file system operations) |
| cuttle os edit | Linux environment only (for file system operations) |
| cuttle devices ssh | Linux environment only (for file system operations) |
| cuttle devices ssh | Linux and macOS environments only (for terminal control) |
Cuttle provides operations output using table or JSON format, table is the
default. To see a response in JSON, add -o json to arguments when invoking
commands. JSON is able to display structures more properly in many cases.
You can add prettifier to the cuttle output if you use json formatting using
| jq . like:
$ cuttle iam list devices --project $PROJECT -o json | jq .
Refer to API manuals of what you can do on EdgeLQ. Cuttle CLI supports all unary and server-streaming commands.
Write operations
Standard write operations are create, update and delete. Note that create
operations allow multiple syntaxes when specifying resource name.
# Create a device resource with specified ID and parent name (containing
# project and region)
$ cuttle devices create device dev-id-1 --parent projects/your-project/regions/us-west2 \
<FIELD-ARGS> -o json
# Create a device resource with a bit different syntax than before.
$ cuttle devices create device dev-id-2 --project your-project --region us-west2 \
<FIELD-ARGS> -o json
# Create a device with a RANDOM ID (since we do not specify ID of a device).
# This command naturally can be invoked with --project and --region too.
$ cuttle devices create device --parent projects/your-project/regions/us-west2 \
<FIELD-ARGS> -o json
# Update a device
$ cuttle devices update device projects/your-project/regions/us-west2/devices/dev-id-1 \
<FIELD-ARGS> <UPDATE-MASK-ARGS> -o json
# Delete a device (no output is provided if no error happens)
$ cuttle devices delete device projects/your-project/regions/us-west2/devices/dev-id-1
Resources usually belong to a project (like resource Distribution in
applications.edgelq.com), or project with region (like resource Device in
devices.edgelq.com). Occasionally some resources have more parent segments:
monitoring.edgelq.com/AlertingConditionhas parentprojects/{project}/regions/{region}/alertingPolicies/{alertingPolicy}.monitoring.edgelq.com/Alerthas parentprojects/{project}/regions/{region}/alertingPolicies/{alertingPolicy}/alertingConditions/{alertingCondition}.iam.edgelq.com/ServiceAccountKeyhas parentprojects/{project}/regions/{region}/serviceAccounts/{serviceAccount}.
Some resources may have multiple parent types (but specific instance can have
only one). For example, resource iam.edgelq.com/RoleBinding has following
parent name patterns:
projects/{project}: Specifies RoleBinding in a Project scope.organizations/{organization}: Specifies RoleBinding in a Organization scope.services/{service}: Specifies RoleBinding in a Service scope.- ``: Specifies RoleBinding in a system (root) scope (they have internal purpose).
$ cuttle iam create role-binding rb-id --parent 'projects/your-project' -o json
$ cuttle iam create role-binding rb-id --parent 'organizations/your-org' -o json
$ cuttle iam create role-binding rb-id --parent 'services/your-service' -o json
$ cuttle iam create role-binding rb-id # In a system scope -o json
Refer to a resource documentation to check possible name patterns.
Resource name serves as an identifier and cannot be changed.
Field arguments
Create/Update operations require typically providing fields for a resource. You need to take a look at a specific resource specification to know list of fields. For example, here you can find specification of monitoring.edgelq.com/AlertingCondition.
Field names must be specified using --kebab-case format, like --display-name here.
$ cuttle monitoring create alerting-condition cnd-id --parent '...' \
--display-name 'VALUE HERE' <MORE-FIELD-ARGS-OPTIONALLY> -o json
Note that you can specify only top fields from a resource. In order to specify a field that contains an object, you must pass JSON string (quoted):
$ cuttle monitoring create alerting-condition cnd-id --parent '...' \
--spec '{"timeSeries":{\
"query":{\
"filter": "metric.type=\"devices.edgelq.com/device/cpu/utilization\" AND resource.type=\"devices.edgelq.com/device\"",\
"aggregation": {"alignmentPeriod":"300s", "perSeriesAligner":"ALIGN_SUMMARY","crossSeriesReducer":"REDUCE_MEAN","groupByFields":["resource.labels.device_id"]}\
},\
"threshold":{"compare":"GT", "value":0.9},\
"duration":"900s"\
}}' <MORE-FIELD-ARGS-OPTIONALLY> -o json
Inside object, all field names must use lowerCamelCase.
When updating
If you are specifying fields for update operations, be careful not to overwrite sub-fields in nested objects by accident! See Update mask arguments.Other top field types (than strings and objects) are:
- booleans (true/false), no quoting needed
- numbers (integers or floats), no quoting needed
- enums - they work like strings
- durations - you need to pass an string with
s. For example300sis a Duration of 300 seconds. - timestamps - format is
YYYY-MM-DDTHH:MM:SS.xxxxxxxxxZ(you can omit sub-seconds though).
Occasionally, you may need to set an array field. For example, there is a field
enabled-services in a iam.edgelq.com/Project resource. Suppose you want
to create a project with 2 services enabled:
$ cuttle iam create project $PROJECT_ID --title $TITLE \
--enabled-services 'services/watchdog.edgelq.com' \
--enabled-services 'services/ztna.edgelq.com'
About updating arrays
If you are making an UPDATE operation on an array, be extra careful. As of now, whole array is being replaced. For example, you have created a project using one service:
$ cuttle iam create project $PROJECT_ID --title $TITLE \
--enabled-services 'services/watchdog.edgelq.com'
If you want to add a new service, you must repeat whole array:
$ cuttle iam update project $PROJECT_ID \
--enabled-services 'services/watchdog.edgelq.com' \
--enabled-services 'services/ztna.edgelq.com' \
--update-mask 'enabledServices'
Specifying only added service will remove previous items.
Update mask arguments
When updating (using update command) a resource using the cuttle command,
be careful about setting unintended zero values.
The update command defines only the top-level fields as arguments, and sets
the lower-level fields as JSON objects in the value. To update only specific
fields in the JSON object and ignore omitted fields, you must specify
an Update Mask.
The following is an example command for setting the value of the spec.osVersion field of the Device resource to 1.0.7.
## This command is dangerous (other fields in the spec are set to zero values)
cuttle devices update device $FULL_NAME \
--spec '{"osVersion": "1.0.7"}'
## run with update mask to achieve intended operation
cuttle devices update device $FULL_NAME \
--update-mask 'spec.osVersion' \
--spec '{"osVersion": "1.0.7"}' \
Clearing a field
If you want to clear a field from a resource, specify update mask argument:
# This will set description to an empty string, whatever value is there.
$ cuttle iam update organization organizations/org-id --update-mask description -o json
Read operations
Read operations are: get, batch-get, list, occasionally search.
# Get a resource
$ cuttle devices get device projects/your-project/regions/us-west2/devices/dev-id-1 \
<FIELD-MASK-ARGS> -o json
# Get 2 resources (note you need to specify param name each time)
$ cuttle devices batch-get devices \
--names projects/your-project/regions/us-west2/devices/dev-id-1 \
--names projects/your-project/regions/us-west2/devices/dev-id-2 \
<FIELD-MASK-ARGS> -o json
# List operation (you can also specify --project and --region instead of --parent)
$ cuttle devices list devices --parent projects/your-project/regions/us-west2 \
--filter '<FILTER STRING>' --order-by '<ORDER BY STRING>' <FIELD-MASK-ARGS> -o json
# Search is like list, but allows for additional --phrase argument. Be aware not
# all resources support search operations. Phrase must always be a string.
$ cuttle devices search devices --parent projects/your-project/regions/us-west2 \
--phrase 'PHRASE STRING' --filter '<FILTER STRING>' --order-by '<ORDER BY STRING>' <FIELD-MASK-ARGS> -o json
Naturally filter, field mask and order by can be omitted if not needed.
Number of resources returned will be limited (100 by default), unless custom page size is configured.
Field mask arguments
By default, if you don’t specify any field mask arguments, service will provide
pre-configured list of fields in a resource that developer configured in advance.
If you compare cuttle output with resource specification, you will see some fields
are usually missing. To provide an additional fields, you can specify extra paths
using --field-mask <lowerCamelCase.nested> arguments (as many as you need).
$ cuttle devices list devices --parent 'projects/your-project/regions/us-west2' -o json \
--field-mask 'status.connectionStatus' --field-mask 'spec.osVersion'
In the result, returned resources will contain pre-configured fields plus additional
specified by --field-mask arguments.
If you don’t want to receive pre-configured paths, just the paths you need, you can
add --view argument:
$ cuttle devices list devices --parent 'projects/your-project/regions/us-west2' -o json \
--view NAME --field-mask 'status.connectionStatus' --field-mask 'spec.osVersion'
View NAME informs a service that it should return only name field of a resources matching
specified parent name. You can then add specific field paths as needed.
Under the hood, cuttle uses actually --view BASIC if you don’t specify a view
at all.
Collection reads within specific scope
Collection requests (list, search) typically require scope specification,
for example using --parent argument. Optionally, specific segments like
--project or --region.
$ cuttle devices list devices --parent 'projects/your-project/regions/us-west2' -o json
# This is equivalent
$ cuttle devices list devices --project 'your-project' --region 'us-west2' -o json
It is also possible to specify wildcards. For example, if we want to query
devices from all the regions within a project, we can use - value:
$ cuttle devices list devices --parent 'projects/your-project/regions/-' -o json
# This is equivalent
$ cuttle devices list devices --project 'your-project' --region '-' -o json
Filtering
Some reading commands allow to use --filter arg. It must be a string with
set of conditions connected using AND operator (if more than one condition
is needed): fieldPath <OPERATOR> <VALUE> [AND ...]. Operator OR is not
supported.
Field path may contain nested paths, each item must be connected with dot ..
Field path items should use lowerCamelJson style.
Operators are:
- Equality (
=,!=,<,>,<=,>=) - In (
IN,NOT IN) - Contains (
CONTAINS,CONTAINS ANY,CONTAINS ALL) - Is Null (
IS NULL) - this type does not require Value.
Certain operators require array value (IN, NOT IN, CONTAINS ANY/ALL). User
needs to use [<ARG1>, <ARG2>, <ARG3>...] syntax.
# List connected devices within specified label
$ cuttle devices list devices --parent 'projects/your-project/regions/us-west2' \
--filter 'status.connectionStatus="CONNECTED" AND metadata.labels.key = "value"' -o json
# List devices using IN conditions
$ cuttle devices list devices --parent 'projects/your-project/regions/us-west2' \
--filter 'metadata.labels.key IN ["value1", "value2"]' -o json
# List devices without specified spec.serviceAccount field path.
$ cuttle devices list devices --parent 'projects/your-project/regions/us-west2' \
--filter 'spec.serviceAccount IS NULL' -o json
# List devices using CONTAINS operation
$ cuttle devices list devices --parent 'projects/your-project/regions/us-west2' \
--filter 'metadata.tags CONTAINS "value"' -o json
# List devices using CONTAINS ANY operation
$ cuttle devices list devices --parent 'projects/your-project/regions/us-west2' \
--filter 'metadata.tags CONTAINS ANY ["value1", "value2"]' -o json
# List alerts with state.lifetime.startTime after 2025 began in UTC (all policies and conditions)
$ cuttle monitoring list alerts --parent 'projects/your-project/regions/us-west2/alertingPolicies/-/alertingConditions/-' \
--filter 'state.lifetime.startTime > "2025-01-01T00:00:00Z"' -o json
Note that name arguments like --parent, --project, or --region are kind
of filter too!
Pagination
Collection requests like list/search offer pagination capabilities. Relevant arguments
are: --order-by, --page-size and --page-token.
To retrieve first page of devices we can do the following:
# Fetch top 10 devices. Since --order-by is not specified, it automatically orders by name
# field in ascending order
$ cuttle devices list devices --parent 'projects/your-project/regions/us-west2' \
--page-size 10 -o json
# This is equivalent command as above, with explicit order
$ cuttle devices list devices --parent 'projects/your-project/regions/us-west2' \
--page-size 10 --order-by 'name ASC' -o json
# This sorts by display name instead in descending order.
$ cuttle devices list devices --parent 'projects/your-project/regions/us-west2' \
--page-size 10 --order-by 'displayName DESC' -o json
It is allowed to sort by one column only as of now. If order by is specified by other field than name, service will sort additionally by name as secondary value though.
After receiving first response, you should see next page token if number of resources is greater than value provided by page size:
{"nextPageToken":"r.e.S.Ckxwcm9qZWN0cy9zY2FsZS10ZXN0LTIvcmVnaW9ucy9lYXN0dXMyL2RldmljZXMvcHAtdGVzdC1wcm92aXNpLXpudHY5OXA4em1meXV5"}
Then, you need to use --page-token argument to fetch the next page. Filter, parent
and order by arguments must be same as before, otherwise results are not defined.
Page size may be optionally changed. Tokens must be treated as opaque strings, not
to be decoded.
$ cuttle devices list devices --parent 'projects/your-project/regions/us-west2' \
--page-size 10 --order-by 'displayName DESC' \
--page-token 'r.e.S.Ckxwcm9qZWN0cy9zY2FsZS10ZXN0LTIvcmVnaW9ucy9lYXN0dXMyL2RldmljZXMvcHAtdGVzdC1wcm92aXNpLXpudHY5OXA4em1meXV5' -o json
After requesting next page, you will have additional data below results:
{
"nextPageToken": "r.e.S.Ckxwcm9qZWN0cy9zY2FsZS10ZXN0LTIvcmVnaW9ucy9lYXN0dXMyL2RldmljZXMvcHAtdGVzdC1wcm92aXNpLXJoa3Vqdmlta3hwNmpv",
"prevPageToken": "l.i.S.Ckxwcm9qZWN0cy9zY2FsZS10ZXN0LTIvcmVnaW9ucy9lYXN0dXMyL2RldmljZXMvcHAtdGVzdC1wcm92aXNpLXpudHY5OXA4em1meXV5"
}
You can then use previous page token to come back to previous results. If you come back
to the first page, prevPageToken will not be present anymore.
To retrieve total results counter, you need to specify -o json --raw-response true --include-paging-info true
in the argument:
$ cuttle devices list devices --parent 'projects/your-project/regions/us-west2' \
--page-size 10 --order-by 'displayName DESC' \
-o json --raw-response --include-paging-info true
Unfortunately, as of now --include-paging-info does not work without
--raw-response, which slightly changes output (stdout gets just full
raw response as JSON).
In the JSON output from response, look out for totalResultsCount value. If
you are paginated results, you will also see currentOffset.
Watch operations
Watch operations are long-running read operations (subscription for updates). There are 3 types:
- Single resource watch
- Stateful collection watch (paged)
- Stateless collection watch (non-paged)
Note: All watch commands require -o json. Without this, you will not get
anything on stdout. You can add | jq . at the end of any command for easier
to read output.
# Watch specific device
$ cuttle devices watch device projects/your-project/regions/us-west2/devices/dev-id-1 -o json
# Watch first 10 devices (stateful)
$ cuttle devices watch devices --parent projects/your-project/regions/us-west2 \
--type STATEFUL \
--page-size 10 --order-by 'displayName ASC' -o json
# Watch devices in a project (stateless). Specify max number of devices in each
# response.
$ cuttle devices watch devices --parent projects/your-project/regions/us-west2 \
--type STATELESS --max-chunk-size 10 -o json
After sending request, user will receive first response (snapshot). Cuttle process however will not quit, but instead hang on, appending more responses to the stdout - real time updates.
Single resource watch
It is very simple watch of a single, specific resource. It works very similar
to get requests, except it provides real-time updates after initial response.
User can specify --field-mask arguments (and --view), just like with get.
Server will skip real time updates if changed fields are not affecting watched fields.
Initial response will contain JSON like (assuming device is a resource name):
{
"added": {
"device": {/* resource body here */}
}
}
If a resource is modified, users will get:
{
"modified": {
"name": "projects/your-project/regions/us-west2/devices/dev-id-1",
"device": {/* resource body here */}
}
}
If a watched resource is deleted, as of now, user will get NotFound error.
Stateful watch
Stateful watch is similar to List, except it provides real time updates following the initial snapshot.
User can specify (just like in list requests):
- Parent/Filter arguments:
--parent(or equivalent in--project,--regionetc.),--filter - Pagination related:
--order-by,--page-size,--page-token - Field masks:
--view,--field-mask
Default page size is 100, if not specified. Default ordering is by name ascending. Effectively, stateful watch observes just a single page.
Initial snapshot (of devices) has following form:
{
"deviceChanges": [
{
"added": {
"device": {
/* ... body ... */
},
"viewIndex": 0
}
},
{
"added": {
"device": {
/* ... body ... */
},
"viewIndex": 1
}
},
{
"added": {
"device": {
/* ... body ... */
},
"viewIndex": 2
}
}
/* ... more entries ... */
],
"isCurrent": true,
"pageTokenChange": {
"nextPageToken": "<TOKEN STRING VALUE>"
},
"snapshotSize": "-1"
}
In stateful watch type, returned resources are sorted, therefore they have
positions. Each added entry contains position in viewIndex field. They
are 0 indexed!
Apart from resource list, additional fields are:
isCurrent: Always true, not relevant for stateful watchessnapshotSize: Always -1, not relevant for stateful watchespageTokenChange: Contains next/prev page tokens, if they changed from previous response. Always included in initial response.
Second and next stateful watch responses will contain only changes that happened on the page that is being observed. It means that:
- Changes on resources outside
--parentor--filterare not received. - Changes within
--parentand--filterthat are in the relevant scope, but outside--order-by,--page-size,--page-token, are also not received. - Only inserted/modified/removed resources are within changes list. For example, if initial list contained 100 objects, and 2 changed later on, subsequent response will contain just 2 objects. Client should update fetched page accordingly. Watch does not send full snapshot each time.
Subsequent responses are like:
{
"deviceChanges": [
{
/* Record added is used for resources that are NEW on this page */
"added": {
"device": {
/* ... body ... */
},
"viewIndex": 16 /* example value */
}
},
{
"modified": {
"device": {
/* ... body ... */
},
/* example values */
"previousViewIndex": 16,
"viewIndex": 16
}
},
{
"removed": {
"name": "projects/your-project/regions/us-west2/devices/deleted-device-id",
"viewIndex": 33 /* example value */
}
}
/* ... more entries ... */
],
"isCurrent": true,
"pageTokenChange": {
"nextPageToken": "<TOKEN STRING VALUE IF CHANGED>"
},
"snapshotSize": "-1"
}
Note there are 3 change types:
added: Informs that selected resource was inserted into the list on some specified position. It includes pre-existing resources that were got position into the list due to the modification.modified: Informs that selected resource on the list was modified. If resource changed position on the list (due to changes in fields pointed by--order-by), thenviewIndexwill be different frompreviousViewIndex.removed: Informs that selected resource was removed from the list. It includes cases when resource modifications that result in resource no longer matching--filterargument. Moreover, it includes cases when resource falls out of a view due to an insertion of a new resource above.
Notes about removed are important: They include not only
deletions and modifications, but also can be sent for resources
that did not change at all. All it takes, is for resource to fall
outside of a view. For example, if we observe top 10 resources,
and new one is created on position 3, two events will be in a
change list:
removed, withviewIndexof value 9added, withviewIndexof value 3
In stateful watch, change list must be applied in same order as in a response
object. This is why, when new resource is inserted, we first have removal,
then addition. If addition was executed first (and view index was 3),
then item in removed object would need to have viewIndex equal to 10, not 9.
Stateless watch
Stateless watch is another collection-type watch (observes list of resources), but has following differences compared to the stateful one:
- Pagination is not supported. Params
--order-by,--page-sizeand--page-tokenhave no meaning. - View indices in responses are meaningless as well, since resources are not ordered at all.
- Initial snapshot may be sent in multiple responses, because they may contain potentially thousands of thousands of resources. This is chunking.
- Responses will contain resume tokens. If connection is lost, client can reconnect and provide last received token to continue receiving updates from the last point.
- Request object can specify resume token, or starting time from which we want to receive updates.
- Response uses different change object types:
currentandremoved, notadded,modified. View index in removed has no meaning.
This watch type is not limited by page size - caller will receive all objects as long as they satisfy parent and filter fields.
There are multiple ways to establish this watch session:
# This will fetch full snapshot of devices in specified project/region
# Then, it will continue with real-time updates.
$ cuttle devices watch devices --parent projects/your-project/regions/us-west2 \
--type STATELESS --max-chunk-size 10 -o json
# This will fetch historic updates from specified timestamp till now, then
# it will hang for real-time updates.
$ cuttle devices watch devices --parent projects/your-project/regions/us-west2 \
--type STATELESS --max-chunk-size 10 --starting-time '2025-01-01T00:00:00Z' -o json
# This will fetch historic updates from resume token till now, then
# it will hang for real-time updates.
$ cuttle devices watch devices --parent projects/your-project/regions/us-west2 \
--type STATELESS --max-chunk-size 10 --resume-token 'sjnckcml4r' -o json
Highlights:
- Max chunk size is optional, 100 if not specified.
- Resume token and starting time should not be used at the same time
- If neither resume token or starting time were specified, backend will deliver full snapshot of resources.
- Resume token can be obtained from previous watch only. It should be treated as opaque string, not to be decoded.
- If resume token or starting time is too far into the past, backend may respond with an error. In that case, it is better to restart watch without neither specified, to get full snapshot.
If full snapshot is specified, then initial responses will look like:
{
"deviceChanges": [
{
"current": {
"device": {
/* ... body ... */
}
}
},
{
"current": {
"device": {
/* ... body ... */
}
}
}
/* ... more entries ... */
],
"isCurrent": true,
"resumeToken": "qdewf3f3",
"snapshotSize": "-1"
}
However, be aware that field isCurrent may be false, and resumeToken empty,
if snapshot turns larger than max chunk size. In that case, client will receive
multiple responses, and only the last one will have isCurrent equal to true,
and resumeToken populated.
In fact, if client receives response without isCurrent equal to true, client
must wait for more responses until this condition is satisfied! This is true
not only for initial snapshot, but any further updates.
After snapshot is received, next responses will have following form:
{
"deviceChanges": [
{
"current": {
"device": {
/* ... body ... */
}
}
},
{
"removed": {
"name": "projects/your-project/regions/us-west2/devices/deleted-device-id"
}
}
/* ... more entries ... */
],
"isCurrent": true,
"resumeToken": "dweqde",
"snapshotSize": "-1"
}
Basically, clients should expect two change types:
current: Can describe creation or update. Resource may, or may not exist prior to the event.removed: This can be deletion, or update that resulted in resource no longer satisfying filter field.
Client should keep track of the last resume token if needed.
Stateless watch type may deliver following special responses:
{
"isSoftReset": true,
"snapshotSize": "-1"
}
If isSoftReset is set to true, client must discard all received changes
after last isCurrent was set to true. Let’s look at scenarios:
No-op scenario:
- Client receives response with non-empty change list, and
isCurrentis true - Client receives response with
isSoftResetset to true. - Client does not need to discard anything, since there were no updates
between soft reset event and last update with
isCurrentequal to true.
With actual reset scenario:
- Client receives response with non-empty change list, and
isCurrentis true - Client receives response with non-empty change list, and
isCurrentis false - Client receives response with
isSoftResetset to true. - Client should discard second message, where
isCurrentwas false.
If isSoftReset is received during snapshot, it means whole snapshot needs
to be discarded.
Other special response that client may receive, is hard reset:
{
"isHardReset": true,
"snapshotSize": "-1"
}
If hard reset is received, client must discard whole data it has. Hard reset will be followed by fresh snapshot.
Finally, there is a possibility of another special message, where snapshot size is equal or greater than 0:
{
"snapshotSize": "1234"
}
If client receives this message, they must check if number of unique resources they have is equal to the snapshot size. If yes, nothing needs to be done. But, if number is wrong, client must disconnect and reconnect without resume token or starting time. This mismatch indicates that some events were lost.
This special message type however is limited to firestore backend type. If service uses mongo, this wont happen.
5 - Help commands
When invoking the cuttle command, you can add the --help option
to see details on how to use each subcommand. This will help you
perform your daily operations more smoothly.